Stimulus Set¶
The launch-release LAION-fMRI stimulus set is a deduplicated collection of 25,052 distinct natural images shown across all five participants. The majority were drawn from LAION-natural - a curated 120-million-image subset of LAION-2B filtered to natural photographs (Roth & Hebart, 2025) - and were chosen by an effective-dimensionality optimisation procedure that promotes uniform coverage of CLIP feature space. Selection was anchored in two established neuroimaging benchmarks by incorporating images from the Natural Scenes Dataset (NSD; Allen et al., 2022) and from THINGS / THINGSplus (Hebart et al., 2019; Stoinski et al., 2024). The THINGS / THINGSplus images additionally overlap with the THINGS-data EEG + fMRI release (Hebart et al., 2023), so analyses on the LAION-fMRI shared set can be compared against results from that dataset as well. The shared set is supplemented with a 371-image out-of-distribution (OOD) test set - visual illusions, Gabor patches, shape stimuli, cropped textures, and similarly unusual configurations - intended as a stress test for encoding and decoding models trained on the natural-image pool.
“Natural images” here means real-world photographs of scenes, objects, and events - illustrations, graphic designs, images with applied filters, and not-safe-for-work content were excluded during manual quality review (see Stimulus Selection for the full screening criteria).
Each participant saw 6,204 unique images across 30 main sessions: 1,492 shared images viewed by every participant (used for noise ceilings and cross-participant comparison) plus 4,712 subject-unique images sampled disjointly from the same pools. Repetition counts and per-session scheduling are documented in Experimental Design; the methodology behind image selection is in Stimulus Selection. Supplemental sessions acquired after the main experiment expand the shared image set to about 2,200 images; those sessions and images will be released later and are not included in the counts below.
Stimulus Sets¶
The shared set has four sources and the unique sets have three. The table below names each contribution and how many repeats it receives in the main experiment; the full selection procedure is in Stimulus Selection.
Source |
Count |
Repetitions |
Notes |
|---|---|---|---|
LAION-natural |
641 |
12 |
Diversity-optimised photographs from the 120M LAION-natural pool |
THINGSplus |
240 |
12 |
CC0 object photographs from the THINGSplus extension; the same images appear in the THINGS-data EEG + fMRI release |
NSD |
240 |
4 |
Cross-study comparability with the Natural Scenes Dataset |
OOD |
371 |
4 |
Visual illusions, Gabor patches, cropped textures, shape stimuli, unusual spatial configurations, gaudy patterns |
Source |
Count |
Repetitions |
Notes |
|---|---|---|---|
LAION-natural |
4,246 |
4 |
Each participant draws from a non-overlapping LAION pool |
THINGS |
144 |
4 |
Object photographs from the original THINGS database; also present in the THINGS-data EEG + fMRI release |
THINGSplus |
322 |
4 |
Additional CC0 object photographs from THINGSplus; also present in the THINGS-data EEG + fMRI release |
Across all five participants the experiment encompasses 25,052 distinct images (1,492 shared + 5 × 4,712 unique). For cross-subject analyses the 1,492 shared images are the natural unit of analysis; for within-subject encoding or decoding, the full 6,204-image per-participant set is available.
Image Format¶
All stimulus images are 1000 × 1000 px, RGB, JPEG-encoded. They are
stored as raw JPEG byte arrays inside task-images_stimuli.h5 in the
same row order as task-images_metadata.csv; the package resolves
image names to rows and decodes images on access.
Where the source image was not already square, the 1000 × 1000 region was selected with DeepGaze (Kümmerer et al.): for each candidate square crop the model predicts a fixation-density map, and the crop maximising total predicted saliency was kept. This preserves the most visually salient image content rather than risking truncation through a naïve centre crop.
On the projector during scanning, the 1000 × 1000 px stimulus subtended roughly 9.2 × 9.2 degrees of visual angle - see Experimental Design for the full presentation geometry.
OOD Test Set¶
In addition to the natural-image pool, 371 out-of-distribution (OOD) images are shipped as part of the shared set, viewed by every participant 4 times. The OOD images deliberately fall outside the LAION distribution and are intended as a held-out test set for measuring how well encoding and decoding models generalise beyond the training distribution. The set covers several visually distinct subcategories:
Classical visual illusions - Müller-Lyer, Ebbinghaus, Kanizsa-style, and similar geometric/perceptual illusions.
Gabor patches - at different orientations, spatial frequencies, and contrasts.
Shape stimuli - simple coloured shapes on plain backgrounds.
Cropped textures - repetitive patterns and material textures with no scene context.
Unusual spatial configurations - objects in implausible positions, scale violations, etc.
Gaudy / high-saturation patterns - strongly chromatic geometric patterns far from the natural-image colour statistics.

A sample of OOD stimuli from the LAION-fMRI shared set.¶
See Train / Test Splits for how to use the OOD set as a held-out test split (Method 3 of the re:vision generalization framework).
File Organization¶
The stimulus set itself is represented by one packed image HDF5 file and one row-aligned metadata CSV:
stimuli/
├── task-images_stimuli.h5 # raw JPEG bytes, indexed by image name
└── task-images_metadata.csv # per-image metadata, row-aligned to the HDF5
Derived stimulus-side files, including image embeddings, captions, and
object segmentations, live in the same stimuli/ directory and are
documented separately in Stimulus Derivatives.
Stimulus Metadata¶
Stimulus-level metadata lives in stimuli/task-images_metadata.csv.
It is the dataset-wide index for the 25,052 stimulus images: one row
per image, with row order aligned to task-images_stimuli.h5.
The primary key is image_name. Use it to join the metadata to the
other stimulus-side files:
task-images_stimuli.h5stores raw JPEG bytes in the same row order.task-images_desc-*_embeddings.h5usesimage_idsvalues that matchimage_name.task-images_desc-captions.csvandtask-images_desc-segmentations_metadata.csvboth carry animage_namecolumn.Per-session events/trial TSV files use the same image names in their stimulus label column.
For how the metadata was collected and computed (visual properties, semantic annotations, model-derived features), see Metadata Acquisition.
Core Columns¶
Column |
Meaning |
|---|---|
|
Filename-style stimulus identifier and primary join key. |
|
Source pool, e.g. LAION-natural, NSD, THINGS / THINGSplus, or OOD. |
|
Participant assignment for subject-unique images; shared images are marked accordingly. |
|
Whether the image belongs to the cross-subject shared set or to one participant’s unique set. |
|
Number of planned experiment repetitions for the image. |
Loading the metadata through the package:
import laion_fmri
stim = laion_fmri.load_stimuli()
metadata = stim.metadata
metadata[[
"image_name", "dataset", "participant",
"unique_or_shared", "n_reps",
]].head()
The same table defines the image names accepted by the image accessor:
name = metadata.loc[0, "image_name"]
image = stim.images.get(name)
Subject-Level Joins¶
For analyses aligned to fMRI trials, use
laion_fmri.Subject.metadata rather than joining events files by
hand. It concatenates the per-session trial tables and adds the
metadata-derived columns image_name, stim_idx,
unique_or_shared, and dataset. The row index is the global trial
index used by sub.images and the derived stimulus accessors
documented in Stimulus Derivatives.
sub = laion_fmri.load_subject("sub-01")
trials = sub.metadata
trials[[
"session", "session_trial", "image_name",
"stim_idx", "unique_or_shared", "dataset",
]].head()
trial = 42
image_name = trials.loc[trial, "image_name"]
img = sub.images.get(trial)
For beta-to-stimulus alignment details, see GLMsingle Beta Estimates.
Distribution of Stimuli¶
To visualise where the different source pools sit relative to one another in image-feature space, every stimulus was projected to two dimensions with t-SNE applied to its OpenCLIP ViT-H/14 embedding (perplexity 30, PCA-50 initialisation).
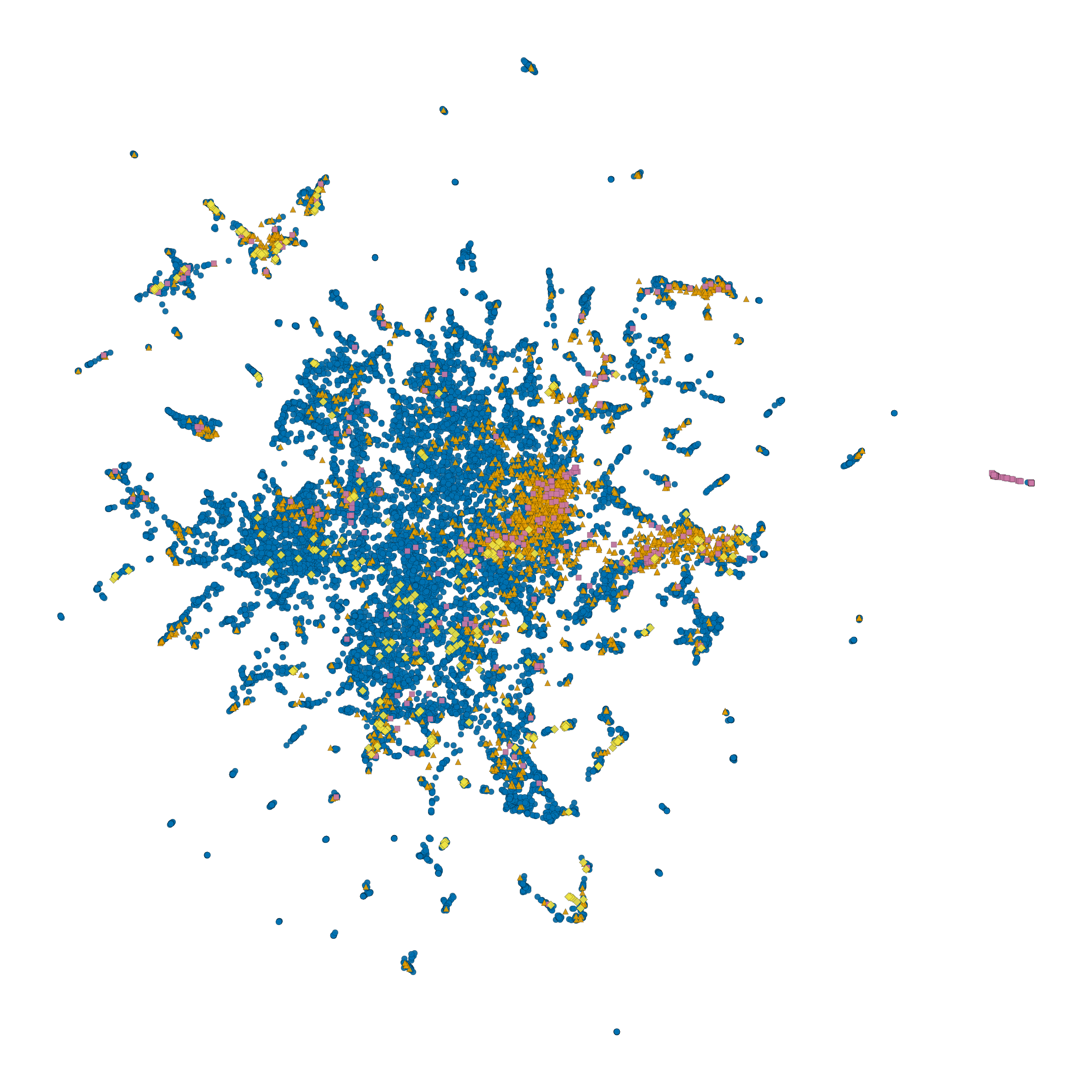
t-SNE projection of the 25,052 LAION-fMRI stimuli in CLIP feature
space, coloured by source pool. The plot is reproducible from
docs/scripts/make_stimuli_tsne.py.¶
Loading the Stimulus Set¶
The laion_fmri package separates downloading from loading:
import laion_fmri
# Raw stimulus images + task-images_metadata.csv.
# See Data Access for raw-image access requirements.
laion_fmri.download_stimuli()
stim = laion_fmri.load_stimuli()
stim.metadata.head() # task-images_metadata.csv
image = stim.images.get(
"shared_12rep_LAION_cluster_1003_i0.jpg",
) # PIL.Image
Subject-level accessors provide trial-aligned views. Use
Subject.metadata for a concatenated trial table with derived
image_name, stim_idx, unique_or_shared, and dataset
columns. The row index of that table is the global trial index accepted
by sub.images.
import laion_fmri
sub = laion_fmri.load_subject("sub-01")
trials = sub.metadata
trial = 42 # global row index in sub.metadata
img = sub.images.get(trial) # PIL.Image
raw = sub.images[trial] # raw JPEG bytes
session_imgs = sub.images.array("ses-01") # (n, 1000, 1000, 3) uint8
See Stimulus Derivatives for pretrained embeddings, object segmentations, captions, and their subject-level accessors. See also Train / Test Splits for how stimuli are partitioned into training and test sets.